Основная терминология
Сегодня мы рассмотрим самые базовые понятия в моделировании данных, которые я буду использовать для описания более сложных вещей. Без понимания этих основ идти дальше будет очень сложно, поэтому очень советую прочитать эту заметку внимательно. А еще я буду давать английский перевод для некоторых понятий.
Термины, которые я хочу объяснить в этой статье:
- Модель данных. Виды модели данных
- Таблицы и атрибуты
- Понятие ключей
- Связи (взаимосвязи, отношения) между таблицами
- ER-диаграмма
Модель данных
Вы не сможете ничего разработать, если у вас не будет модели данных. То есть это вообще самое первое, что нужно иметь, перед тем как приступать к разработке вашей базы данных. Более того, если вы сделали плохую модель данных, это вам потом вернется большими проблемами при масштабировании, добавлении новых таблиц и атрибутов. Или багами на продакшене (я даже не знаю, что может быть страшнее).
Теперь, когда я всех напугал, давайте дадим определение модели данных. Модель данных - это абстрактное визуальное представление того, как данные будут организованы и структурированы в вашей будущей базе данных.
Для визуального представления используют ER-диаграммы (entity-relationship). Исходя из названия, можно догадаться, что такая диаграмма показывает отношения (relationship, отношение) между таблицами/сущностями (entity).
Существует 3 вида моделей данных:
- Концептуальная (conceptual data model),
- Логическая (logical data model),
- Физическая (physical data model).
Каждая из них используется для разных целей и ими пользуются разные люди.
Но вы, как бизнес/BI/какой угодно другой аналитик будете их разрабатывать и пользоваться всеми. Такова жизнь.
Перед тем как хоть что-то разработать, нужно понять, а что мы хотим сделать. Я сейчас не буду описывать весь цикл разработки, это отдельная большая тема, важно то, что для сбора верхнеуровневых требований нам достаточно иметь Концептуальную модель данных. Именно эту модель можно показывать вашим бизнес-заказчикам, чтобы все понимали, что происходит.
Например, наш клиент - это районная библиотека, которая хочет внедрить систему учета книг. Начинаем, естественно, с концептуальной модели, чтобы понять, а что мы хотим в принципе хранить.
От заказчика мы узнаем, что нам нужно хранить информацию о книге, информацию об авторе и место в самой библиотеке, где хранится книга.
Выглядит концептуальная модель как-то так:
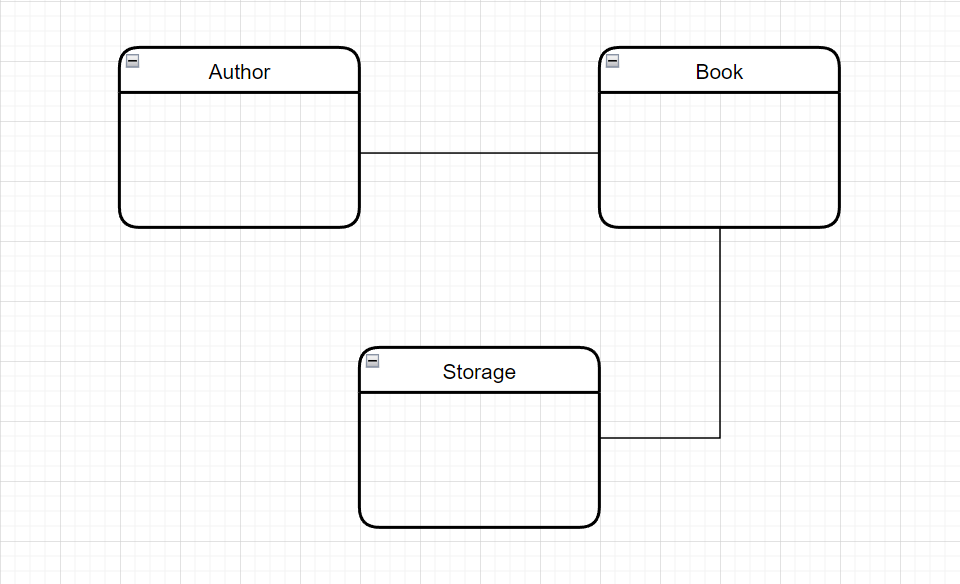
Ну, то есть понятно, что это очень концептуальная и верхнеуровневая схема, которая определяет предметную область того, что мы хотим сделать. На этой схеме есть только названия сущностей и связи между ними. Очевидно, что этого явно недостаточно, для того, чтобы начинать творить.
Пока мы видим только объекты информации, бизнес-сущности, но пока не знаем, какая информация будет хранится в рамках этих верхнеуровневых сущностей.
Мы начинаем расспрашивать наших заказчиков и возможных пользователей о том, какую информацию необходимо хранить. Мы узнаем, что для каждой книги мы должны хранить название, издательство, год издания, место на полке в библиотеке. Об авторе мы хотим хранить его фамилию и имя, а также год рождения.
Здесь уже начинается настоящее дата моделирование. Основные принципы мы рассмотрим в этой и в этой статьях, а пока придется принять на веру, что я все делаю правильно. Почему появилась таблица book_detail я расскажу чуть позже в этой статье.
В логической модели данных помимо сущностей и взаимосвязей мы уже указываем атрибуты (это синоним слову столбцы/колонки/поля в физической модели данных), первичный и внешний ключи (про ключи мы поговорим позже в этой статье).
Вот что у меня получилось:
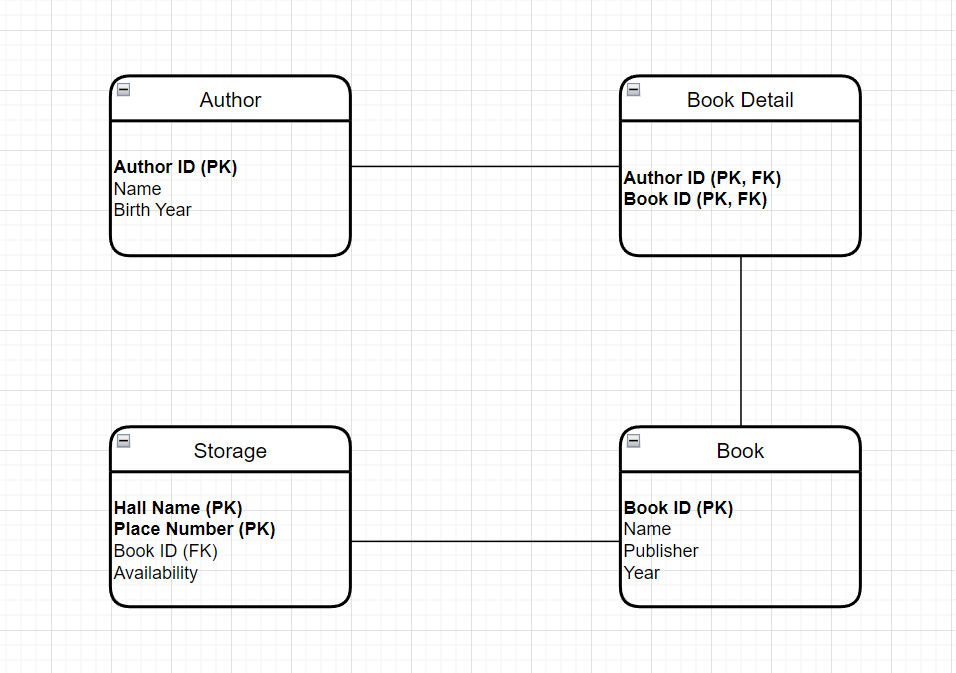
Выглядит уже гораздо наряднее, это уже можно показывать ведущему аналитику, архитектору и другим коллегам, чья роль на стыке между бизнесом и разработкой. Можно даже еще кому-нибудь показать, но помните о соглашении о неразглашении информации (NDA).
Но если вы отдадите это разработчику, он вас замучает вопросами. А как мне назвать столбцы в таблицах? А какие типы данных для столбцов? Нужно ли мне какие-то ограничения задавать? Есть два варианта - прятаться от разработчика и не отвечать на его/ее звонки. А можно подготовить физическую модель данных и уже ее отдать в разработку.
На данном этапе наши сущности превращаются в таблицы.
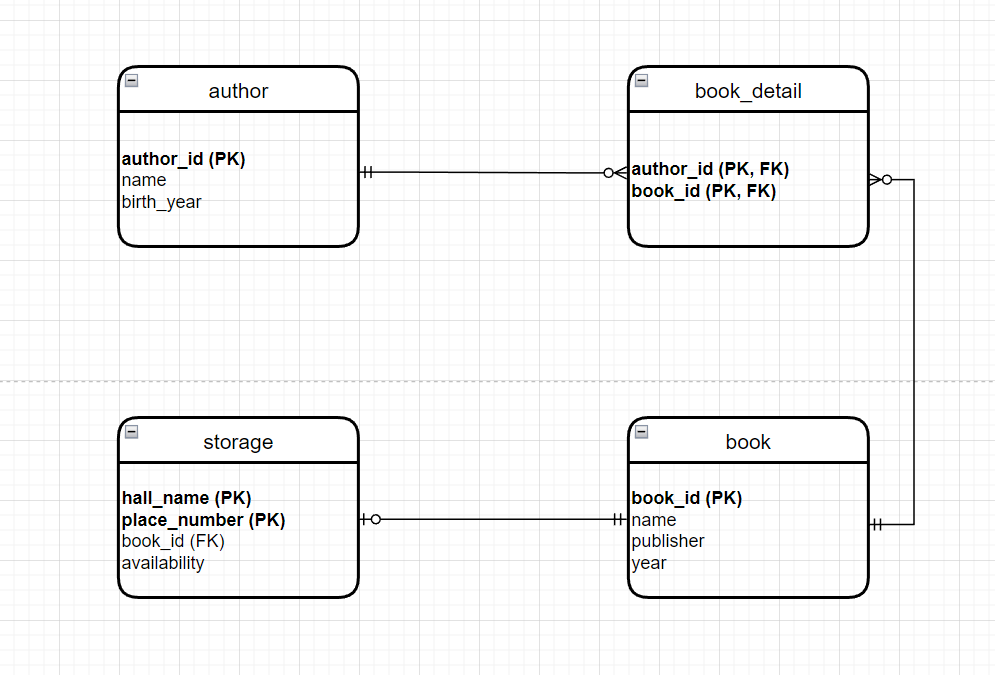
Кстати, обратите внимание, что помимо того, что немного изменились названия таблиц и атрибутов, появились типы данных, а также изменились стрелочки.
То, что у нас изменились стрелочки - это называется IE (information engineering) notation или в простонародье Crow's foot notation (воронья лапка).
Более подробно мы поговорим о взаимосвязях далее в этой статье.
Названия таблиц и атрибутов изменились, потому что именно так они будут называться в нашей базе данных, это можно назвать "физические наименования" (physical names). Русский перевод звучит немного коряво, конечно.
Давайте подведем итоги и попытаемся визуализировать то, что мы обсудили выше:

Ключи
Прежде чем разобраться в этих сакральных знаниях давайте посмотрим, а каким типы ключей бывают:
- Первичный (primary key) и внешний (foreign key)
- Простой (simple key) и составной (compound/composite key)
- Естественный (natural key) и суррогатный (surrogate key)
Начнем с первичного и внешнего ключа. Первичным ключом (primary key) называют такой атрибут (или несколько атрибутов), которые однозначно идентифицируют запись в таблице. Когда первичным ключом являются несколько атрибутов, такой ключ называют составной.
Первичный ключ может быть естественный - это значит, что вы не придумываете ничего лишнего и берете уже существующий в природе атрибут для уникального идентификатора. В нашем примере это hall_name (название зала) и place_number (номер места). Это первичный составной естественный ключ.
Внешний ключ - это такой атрибут, который ссылается на первичный ключ другой таблицы. У нас таким атрибутом, например, является book_id в таблице storage. А это нас подводит к еще одному важному понятию, родительская таблица (parent table) - та таблица которая содержит первычный ключ, на который ссылается внешний ключ дочерней таблицы (child table). То есть book_detail - это дочерняя таблица, author - родительская таблица.
Суррогатный ключ - это искусственно созданный, сгенерированный системой ключ. Это может быть простая последовательность (1, 2, 3, ...), может быть UUID (специальный общепринятый формат) и тд. В нашем примере - это author_id. Конечно, можно было бы придумать и выбрать для этой таблицы естественный ключ. Но вдруг, у нас есть два автора с одинаковыми ФИО и одним годом рождения? Тогда эти два поля уже уникально не определяют одну запись. Тогда нужен еще один атрибут, например, девичья фамилия матери (прошу прощение за безумие). Но если атрибут становится первичным ключом на него накладывается ограничение (constrain), что он обязательно должен содержать хоть какое-то значение, т.е. он не может быть NULL. А вдруг эта информация нам не всегда доступна?
С книгой проще, book_id может быть ее инвентарный номер, а значит вполне себе естественный ключ.
На самом деле - это великий холивор между двумя лагерями сторонников естественных ключей и суррогатных ключей. Я в этом участвовать не хочу, спорить ни с кем не буду, чего и вам советую.
Есть плюсы и минусы использования суррогатных ключей, например, из плюсов:
- уникальность (если, конечно, ваши алгоритмы нормально работают)
- неизменность (с этим надо тоже быть очень осторожным и не переоценивать это преимущество)
- есть и другие, но я считаю это основными
из минусов:
- неинформативность (например, UUID: 4040f71a-614e-47cc-8df7-1d988855d2c4... эээ что это?)
- возможные ошибки
- потенциальные вопросы к оптимизации (это довольно сложная история с индексами и может быть важна только на действительно огромных объемах данных)
Чтобы как-то подытожить эту пространную тягомотину, я могу посоветовать следующее - используйте то, что удобнее для вас в конкретной ситуации.
Получилось немного сложно, но в конце-концов люди за это деньги получают. Было бы просто - все были бы дата моделлерами.
Чтобы закончить эту тему я расскажу один интересный факт (хотя моя жена вряд ли сочла бы его интересным). Вы можете его забыть напрочь, потому что это вообще неважно, но можно однажды блеснуть им в курилке. В английской литературе разделяются понятия Compound key и Composite key. Кажется, в русском дата моделировании нет никакой разницы, но вот у уважаемых западных партнеров Compound key - это такой составной ключ, который содержит в себе в том числе и внешний ключ. Например, в таблице book_detail первичный ключ является Compound key, потому эти атрибуты являются одновременно и первичным составным ключом и внешними ключами. Composite key - это просто составной ключ, который может включать, а может и не включать внешний ключ. По умолчанию, можно любой составной ключ называть Composite primary key.
Статья уже получилась огромная, но мы же не собираемся останавливаться на полпути? Вообще, я буду удивлен, если до этого места хоть кто-то дочитал.
Связи
Связи, отношения... А вообще есть разница?
Вообще, конечно, есть, иначе я был не спросил об этом. Очень часто, да, на самом деле, всегда, эти понятия используются синонимично, но я сегодня вредный и поэтому предложу вам окунуться в детали.
Связь - это по сути абстрактная стрелочка от одной таблице к другой. Конечно же, в настоящей базе данных нет никаких стрелочек, но есть ограничения. Об одном из них мы говорили выше, ниже поговорим еще об одном.
А что такое отношение? Это связь с характеристикой ссылки внешнего ключа на первичный ключ. Ой, сейчас даже мне стало неприятно, но давайте разбираться, что я тут нагородил.
Сделаем шаг назад и перечислим какие отношения (ну или называйте их связями, это тоже правильно):
- Один к одному
- Один ко многим
- Многие ко многим
Забегая вперед и чтобы запутать вас еще больше скажу - многие ко многим - это очень плохо и в физической модели данных такого быть не должно. Обещаю, это я тоже объясню.
Итак, один к одному. Это довольно редкая связь, потому что проще сделать одну таблицу, чем делать две со связью 1 к 1. Но вот в нашем случае мы решили создать отдельную таблицу storage. Сейчас не будем вдаваться в детали моделирования данных, все наши примеры иллюстративные. Логика простая, одна конкретная книга может храниться только в одном определенном зале на одном месте на стеллаже.
Один ко многим - это самая распространенная связь и вообще надо всегда стараться делать ее, когда моделируете данные. Такую связь еще называют 1:N и это значит, что одной записи в таблице А соответствует несколько записей в таблице Б. И вообще таблица А является родительской по отношению к таблице Б, потому что первичный ключ таблицы А является внешним ключом таблицы Б. Я сейчас специально все смешал в одну кучу, чтобы разбираться было интереснее У нас такие связи две - это author и book_detail, book и book_detail. Постарайтесь сами догадаться, почему это один ко многим. Вот смотрите, у нас в таблице author существует только один автор с определенным author_id, а в таблице book_detail этот самый автор с этим самым author_id может встречаться несколько раз с разными book_id. Ну потому что один автор может написать несколько книг, это логично.
Многие ко многим. Вот это нужно избегать. И, кстати, у нас такая связь могла бы быть, если бы не существовало таблицы book_detail. Ну все-таки чего-то я знаю, поэтому ее и нарисовал. Русский термин для такого вида таблиц мне пришлось гуглить и русское название "таблица-мост" (bridge table). Ну я, в принципе, понимаю, почему их никто русским термином не называет. Так, что за мост-то такой? Дело в том, что у одного автора может быть несколько книг. И одна книга может быть написана несколькими авторами, это связь многие ко многим. А теперь давайте попробуем представить как могли бы выглядеть эти две таблицы author и book, без таблицы book_detail. Например, в таблицу автор добавляем внешний ключ book_id, а в таблицу book добавляем внешний ключ author_id и все хорошо. Ну вот и нет. Вспоминаем, что первичный ключ - это уникальный идентификатор, у нас не может быть несколько записей в таблице с одним и тем же первичным ключом. Берем таблицу author, и некий автор написал несколько книг, например, 3 штуки. Это значит, что в таблице author мы встретим 3 записи с одним и тем же первичным ключом author_id и тремя разными внешними ключами book_id. Аналогичная ситуация с таблицей book. Поэтому, чтобы избежать подобной проблемы мы создаем промежуточную таблицу (это не совсем верный термин, но от таблицы-мост мне просто плохо становится) book_detail. И это удобно, потому что у нас получается составной первичный ключ author_id + book_id и он никогда не будет повторяться. Зато мы знаем все сочетания авторов и книг и при необходимости сможем написать запрос с использованием двух операторов JOIN. Про sql-запросы поговорим в следующих статьях.
Мне кажется должно быть понятно. Если все равно не очень понятно, перечитайте про первичный ключ и попробуйте смоделировать отношение студент и курс. Где один студент может посещать несколько курсов и на одном курсе может быть много студентов.
Статья получилась просто огромная, но нам нужен еще один рывок, чтобы разобраться со стрелочками и почему они такие странные. Терпим.
Crow's foot notation Русское название я гуглить не стал, потому что если это правда называется по-русски вороньей-лапкой, то это просто несерьезно. И здесь мы дадим определение термину кардинальность (cardinality). А точнее сошлемся на то, о чем я писал выше