Нормальные формы
На самом деле, это одна из самых важнейших тем нашего пособия, если не самая главная в принципе. Это база, без которой невозможно нормально и правильно проектировать транзакционные системы. Да и хранилища без ее понимания невозможно проектировать тоже.
Сегодня мы с вами поговорим, что такое нормальные формы, для чего они нужны, подробно рассмотрим три основные (потому что они в основном и используются на практике), а еще в процессе составим небольшую модельку, которая будет отвечать всем главным трем нормальным формам. Почему фокусируемся только на 3х формах будет понятно в конце статьи, так что читайте до конца.
Кстати, я специально буду избегать сложных терминов для реляционных баз данных типа "сущность" (таблица), "кортеж" (строка или запись в таблице), потому что это на Википедии можно прочитать или в университетских лекциях - сложно и непонятно. В конце-концов, как вы ведущему аналитику будете про кортежи в отношениях рассказывать?

Так что такое нормальные формы?
Грубо говоря, нормальная форма - это то требование (или еще это можно назвать свойством), которому должна соответствовать наша модель данных, а соответственно и структура таблиц будущей базы данных. Всего их, кстати, официально целых 8, вот они:
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
большинство останавливаются здесь
- Нормальная форма Бойса — Кодда (BCNF)
отсюда начинается нечто непостижимое
- Четвёртая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Зачем нам нужны какие-то специальные условия? Ну потому что иначе у нас могут появится дубли строк, а также всякие аномалии, которые мы рассмотрим чуть далее на примерах.
Пока, кажется, ничего не понятно, но ничего, дальше будет хуже.
Для простоты изложения представим, что нам пришла задача - разработать базу данных для хранения информации о студентах и курсах. Давайте разбираться.
Начнем с первой нормальной формы
Итак, сразу начнем с определения: Можно считать, что таблица находится в нормальной форме, если все значения в столбцах (атрибутах) этой таблицы простые (ничего через запятую не перечисляем), строки не повторяются.
Так вот, вы стали пытаться создать свою первую таблицу Students:
| name | uni | project | duration | grant |
|---|---|---|---|---|
| Иванов И., Егоров О. | МГУ | А1, Б1 | 1, 2 | 100 |
| Петрова Л., Львов Л. | МГТУ | Б1, Б1 | 2, 2 | 95 |
| Сидоров И. | МГУ | А1 | 1 | 100 |
В данной максимально искусственной таблице, поле name - это имя, uni - университет, project - код группового проекта, duration - длительность проекта в месяцах, grant - стипендия.
Таблица явно не в первой нормальной форме. А почему это вообще плохо?
А потому что нас могут возникнуть аномалии. Жуть.
Аномалия - это когда у нас возникает противоречие данных, и наша БД будет содержать некорректную информацию. Бывают аномалии редактирования, добавления и удаления.
Как эти аномалии применимы для нашей конкретной таблицы.
Например, мы вдруг осознали, что хотим удалить студентов участвующих в проекте Б1. Я не знаю, что произошло, но вот так мы решили. Соответственно мы даем задание админу БД удалить информацию об экономике и он со спокойной душой сносит всю информацию о студентах, у которых project = 'Б1'. А вот Иванов И. вообще на проекте А1, его за что? Это аномалия удаления.
Или же, мы узнали, что необходимо повысить степендию для университета МГУ. Сейчас это 100 рублей, а стало 110 (представим, что для каждого университета у нас своя стипендия). Ок, сейчас у нас всего несколько записей и мы вручную можем это поправить. А вдруг человек, редактирующий данные не в курсе, сколько строк нужно поправить? А если у нас, например, 1000 записей и он какую-нибудь пропустит? Это называется аномалия редактирования.
Ну, а аномалия добавления - это когда нам нужно что-то добавить в нашу таблицу, а для обязательного поля у нас просто нет данных. Например, у нас появился новый студент, адреса которого мы пока не знаем. А так как поле обязательное, нам придется выдумывать несуществующую информацию, чтобы заполнить таблицу.
Как это все чинить - конечно, приводить к третьей нормальной форме!
Давайте сначала приведем таблицу к 1НФ:
| name | uni | project | duration | grant |
|---|---|---|---|---|
| Иванов И. | МГУ | А1 | 1 | 100 |
| Егоров О. | МГУ | Б1 | 2 | 100 |
| Петрова Л. | МГТУ | Б1 | 2 | 95 |
| Львов Л. | МГТУ | Б1 | 2 | 95 |
| Сидоров И. | МГУ | А1 | 1 | 100 |
Стало чуть лучше, потому что Иванова хотя бы не удалят, когда будут стирать инфу про проект Б1.
Что дальше?
Итак, вторая нормальная форма
А вот пока нет. Для этого нам надо ввести понятие первичного ключа. Вообще, для более подробного определения и примеров см. предыдущую стать статью, но я попробую в двух словах объяснить суть концепции. Первичным ключом (primary key) называют такой атрибут (или несколько атрибутов), которые однозначно и бесповоротно идентифицируют запись в таблице. В нашем случае это будут 2 атрибута name и project. Конечно, в реальной жизни, наверное, у нас могут быть полные тезки на одном проекте, но давайте для упрощения представим, что в нашей студенческой группе так не бывает. Итак, перед вами составной первичный ключ. Составной, потому что он состоит из нескольких атрибутов.
А теперь определение второй нормальной формы - таблица находится во второй нормальной форме, если она уже находится в 1НФ, а также каждый ее неключевой атрибут (тот который не входит в состав первичного ключа) зависит от каждого атрибута составного ключа. Когда неключевой атрибут зависит только от части первичного ключа - это называется функциональная зависимость.
Немного сложно, но давайте на примере. В нашем случае у нас есть поле duration, которое зависит только от части первичного ключа. Попробуйте посмотреть на таблицу и самостоятельно догадаться.
| name | uni | project | duration | grant |
|---|---|---|---|---|
| Иванов И. | МГУ | А1 | 1 | 100 |
| Егоров О. | МГУ | Б1 | 2 | 100 |
| Петрова Л. | МГТУ | Б1 | 2 | 95 |
| Львов Л. | МГТУ | Б1 | 2 | 95 |
| Сидоров И. | МГУ | А1 | 1 | 100 |
Поле duration зависит от поля project, но не от поля name. Неважно какая фамилия, значение атрибута duration меняется только с изменением значения атрибута project
Так что же делать? На самом деле, есть два варианта:
- Мы можем придумать суррогатный ключ - это искуственный ключ, который будет служить первичным ключом. Например id, которая будет хэш функцией от значений атрибутов name и project. Да, так тоже делают. Если у таблицы первичный ключ не составной, она автоматически оказывается во второй нормальной форме.
- Вынести атрибут duration в отдельную таблицу, вместе со всеми его функциональными зависимостями, чтобы не мешал жить нормальным атрибутам - это называется декомпозиция
Таким образом, имеем две таблицы:
Students:
| name | uni | project | grant |
|---|---|---|---|
| Иванов И. | МГУ | А1 | 100 |
| Егоров О. | МГУ | Б1 | 100 |
| Петрова Л. | МГТУ | Б1 | 95 |
| Львов Л. | МГТУ | Б1 | 2 |
| Сидоров И. | МГУ | А1 | 100 |
Projects::
| project | duration |
|---|---|
| A1 | 1 |
| Б1 | 2 |
Почти идеально. Если кто-то захочет поправить длительность проекта, он это сделает в одной записи в таблице projects. Но все же несовсем.
Обратите внимание, значение атрибута grant зависит от атрибута uni. Вспоминаем пример с аномалией редактирования.
Третья нормальная форма
Сразу начинаем с определения - таблица находится в 3НФ, если она находится во 2НФ и все неключевые атрибуты не находятся в зависимости от других неключевых атрибутов. В нашем случае мы наблюдаем транзитивную зависимость (то есть неключевой атрибут зависит от ключевого атрибута, но не напрямую, а только через другой неключевой атрибут, ААА СЛОЖНО): атрибута grant от атрибута uni. Ну то есть, grant не зависит от name и project (а это наш составной первичный ключ).
Итого имеем 3 таблицы!
Students:
| name | uni | project |
|---|---|---|
| Иванов И. | МГУ | А1 |
| Егоров О. | МГУ | Б1 |
| Петрова Л. | МГТУ | Б1 |
| Львов Л. | МГТУ | Б1 |
| Сидоров И. | МГУ | А1 |
Projects:
| project | duration |
|---|---|
| A1 | 1 |
| Б1 | 2 |
Grants:
| uni | grant |
|---|---|
| МГУ | 100 |
| МГТУ | 95 |
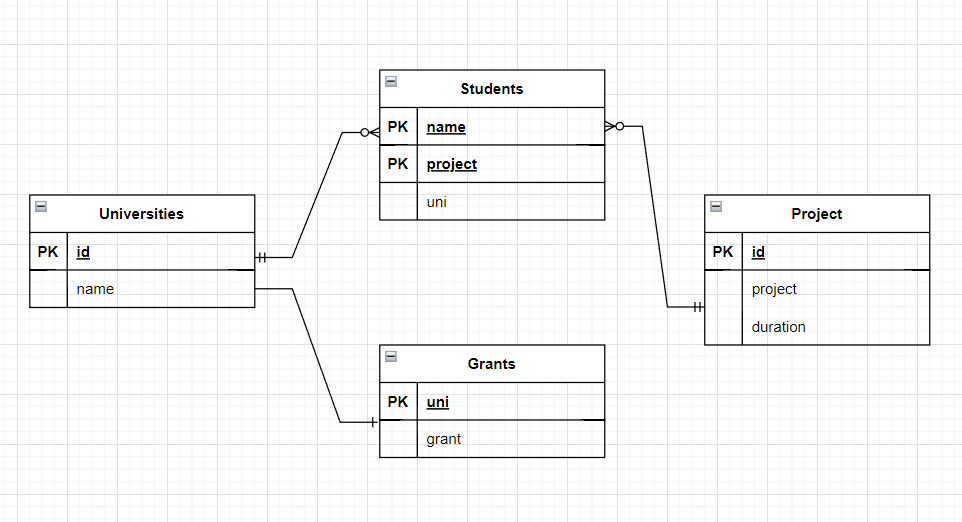
Фух, разобрались! Единственное, что я бы еще сделал, это вынес названия университетов в отдельную справочную таблицу. Итого 4 таблицы:
Students:
| name | uni | project |
|---|---|---|
| Иванов И. | 1 | 1 |
| Егоров О. | 1 | 2 |
| Петрова Л. | 2 | 2 |
| Львов Л. | 2 | 2 |
| Сидоров И. | 1 | 1 |
Теперь в таблице Students вместо названия университета - его идентификатор. Это необходимо опять же для того, чтобы при изменении названия университета необходимо было править только одну таблицу.
Также добавим идентификатор в таблицу Projects с той же целью.
Projects:
| id | project | duration |
|---|---|---|
| 1 | A1 | 1 |
| 2 | Б1 | 2 |
Universities:
| id | name |
|---|---|
| 1 | МГУ |
| 2 | МГТУ |
Grants:
| uni | grant |
|---|---|
| 1 | 100 |
| 2 | 95 |
А вот и обещанная модель данных:
Нормальная форма Бойса — Кодда (BCNF)
Я не был уверен, стоит ли объяснять данную нормальную форму тоже, но все-таки решил рассказать и про нее. Дело в том, что иногда ее используют и знать о ней, как минимум, полезно. А как максимум - это приятно и можно впечатлить коллег. Эту нормальную форму еще называют усиленной 3НФ. Как и 2НФ она применима только к таблицам с составным первичным ключом. Итак, таблица находится в BCNF, если она находится в 3НФ и все части первичного ключа не зависят от неключевых атрибутов.
Сразу на примере. Давайте представим, что у каждого проекта у нас есть еще куратор.
И мы, недолго думая, решили добавить этот новый атрибут в таблицу Students:
Students:
| name | uni | project | curator |
|---|---|---|---|
| Иванов И. | 1 | 1 | Краснов А. |
| Егоров О. | 1 | 2 | Носов П. |
| Петрова Л. | 2 | 2 | Носов П. |
| Львов Л. | 2 | 2 | Носов П. |
| Сидоров И. | 1 | 1 | Краснов А. |
Несмотря на то, что таблица находится в 3НФ, и, вроде бы, все хорошо. Но мы можем заметить, что поле project (часть составного ключа) зависит от поля curator. Дело в том, что зная куратора, мы можем понять и курируемый им проект.
Значит поле curator необходимо добавить в таблицу Projects, а из Students беспощадно удалить.
Projects:
| id | project | duration | curator |
|---|---|---|---|
| 1 | A1 | 1 | Краснов А. |
| 2 | Б1 | 2 | Носов П. |
Теперь точно все. Использование других нормальных форм я на практике никогда не встречал, поэтому не буду даже пытаться описывать. Да и это все равно очень вряд ли когда-нибудь кому-нибудь пригодится. Это объясняется тем, что дальнейшая нормализация будет приводить к потере производительности.
Давайте ещё раз вспомним, что мы сегодня обсудили:
- 1НФ - значения простые, строки не дублируются
- 2НФ - все неключевые атрибуты зависят от составного первичного ключа
- 3НФ - нет зависимостей между неключевыми атрибутами
- Форма Бойса — Кодда - ключевые атрибуты не зависят от неключевых атрибутов
А я на сегодня все. Всем пока!